Relativity Analytics Part Three: Textual Near Duplicates

Relativity Analytics Part Three: Textual Near Duplicates

CYFOR Relativity blog part three: eDiscovery Specialist Luke Holden covers the benefits of the Textual Near Duplicates process and its effectiveness during disclosure.
Textual Near Duplicates
When reviewing documents for disclosure, restrictive deadlines are often imposed without consideration being given to the intricacies of the document review process. This can put pressure on a legal team, particularly those with fewer resources, to review a large number of documents in a short space of time.
If a thorough document review is not undertaken, key documents may be overlooked, which can cause significant issues at later stages in the litigation. It is therefore important to manage document review to ensure that the process remains both efficient and rigorous.
The more documents there are to review, the longer a review will take. Therefore, the larger the overall data set, the further you are from completing your review in time to meet imposed deadlines. While it may be possible to apply more resources to the task or seek an extension, some options may be costly.
Using the software tools available within Relativity, it is possible to reduce the size of the overall data set, therefore decreasing the time and resources required to complete your review. Textual near duplicate identification is one such software tool that will help you reduce your overall review time.
Duplicate documents can cause issues throughout the document review process. It is necessary to remove duplicate documents, those with identical content, from the overall review data set and reduce the likelihood that a reviewer will need to appraise the same document more than once. When documents are first published to the Relativity platform, an automated de-duplication process can be carried out to remove documents which are identical in every way; for example, a document that has the same content, the same author and is the same format. This process assists in isolating unique documents and reducing the overall volume of data at an early stage.
Potential Limitations
However, this automated de-duplication process has limitations. The software that is used to carry out de-duplication is based on one criteria, that the digital fingerprint of a document is identical to another. Should any element of a document change, no matter how small, the system will no longer be able to identify that document as a duplicate of another. For example, the digital fingerprint can be changed by something as simple as adding one word to a document, removing a signature or saving it in PDF format instead of Word format. This means that documents that appear to be identical are not identified as such by the system.
To demonstrate, consider an email with the below text content:
Good morning Michael,
I hope you are well. I have transferred the funds to your account, so they should be with you shortly.
Kind regards,
Kirsty
Then consider the email, but with a single alteration:
Good morning Michael,
I hope you are well? I have transferred the funds to your account, so they should be with you shortly.
Kind regards,
Kirsty
The only difference between the above two emails is the punctuation following the text ‘I hope you are well’. One email uses a full stop as punctuation, the other a question mark. Outside of this, the text content of the email is identical. The alternative use of punctuation is enough to change the digital fingerprint of the document and it would not be automatically de-duplicated. This document would then be provided in the overall data set and would need to be reviewed twice.
Textual near duplicates identification analyses the text content of all documents and determines a percentage similarity for each document in comparison with all others. This process then groups together documents, based on similarity.
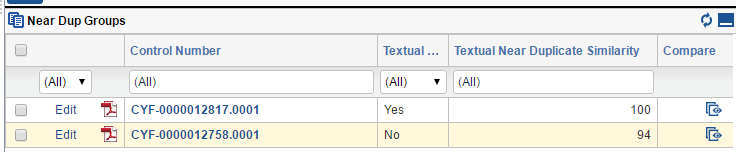
This allows reviewers to quickly identify those documents that may be similar enough to an already reviewed document and do not require further review. All duplicate documents that contain identical text content, and a similarity percentage of one hundred, can be isolated from review completely.
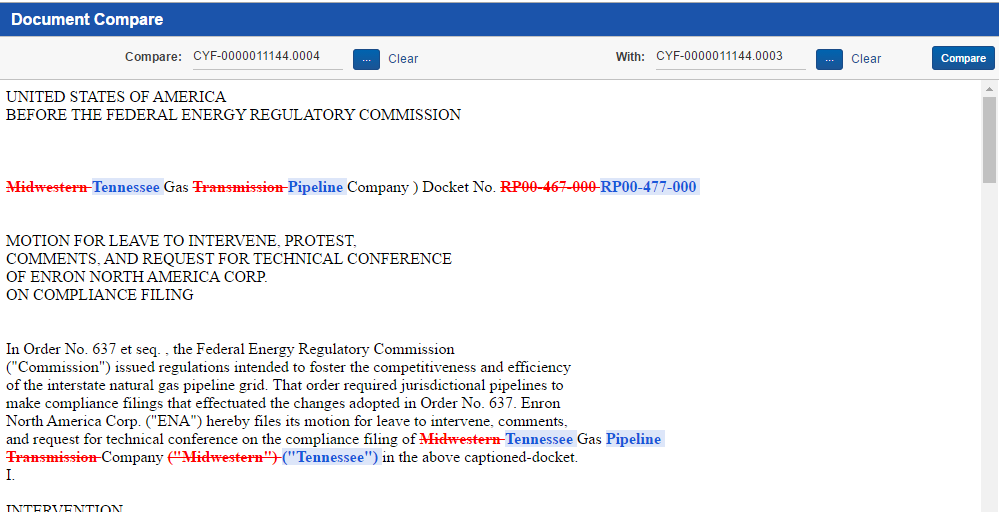
Relativity also allows you to compare documents with similar text content, to easily identify differences. This enables reviewers to make a quick decision on documents that are textually similar but not identical, as to whether further review is required.
In the example below, two Word documents are being compared using textual near duplicate identification. All red text, scored through with a line, represents text that has been changed, and the text highlighted blue represents the replacement text.
By using the textual near duplicates identification tool, as well as other Relativity features, you can speed up your review process from start to finish, saving time and money. Relativity also allows smaller teams to manage reviews that would traditionally require a larger number of additional resources.
Call us today and speak with a Forensic Specialist
Send an enquiry to our experts
After submitting an enquiry, a member of our team will be in touch with you as soon as possible
Your information will only be used to contact you, and is lawfully in accordance with the General Data Protection Regulation (GDPR) act, 2018.