Relativity Analytics Part One: Clustering

Relativity Analytics Part One: Clustering

The first in a series of informative eDiscovery blogs written by the senior experts within CYFOR. Part One, written by eDiscovery Specialist Paula Forrest, explores the benefits of Clustering within Relativity Analytics.
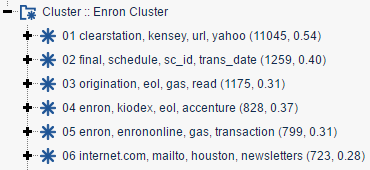
Clustering is a key feature within Relativity’s analytics engine and is particularly useful in cases where the client needs to quickly assess the content of the data set. This tool uses the analytics index to identify groups of documents based on their conceptual similarity. The groups of documents are placed into clusters and assigned a name based on their conceptual content.
The example outlined below and throughout the blog use the Enron dataset. This is an open source dataset that is extensively used for training and visual representation examples;
Cluster Visualisation
Clustering can be carried out on the entire data set or on a specific set of documents using a saved search. This might reflect a relevant date range or custodian of interest. This can also help drill down further into the data set. A quick review of the clusters can immediately draw out groups of documents that may be important to the case. It also aids decision making in terms of review and workflow by providing an overview of the key concepts or topics across the entire data set.
Clustering can also be useful to help prioritise review. In instances where deadlines are tight and a full review is unachievable, documents can be batched out to clients based on the clusters deemed most relevant to the case. The review team can review the key documents as priority and work through the remaining clusters at a later date.
To allow the user to achieve a clearer view of the data, Relativity incorporates a feature called cluster visualisation. As represented below, this tool places the clusters into a circle pack, with the largest circle representing the cluster containing the greatest number of documents.
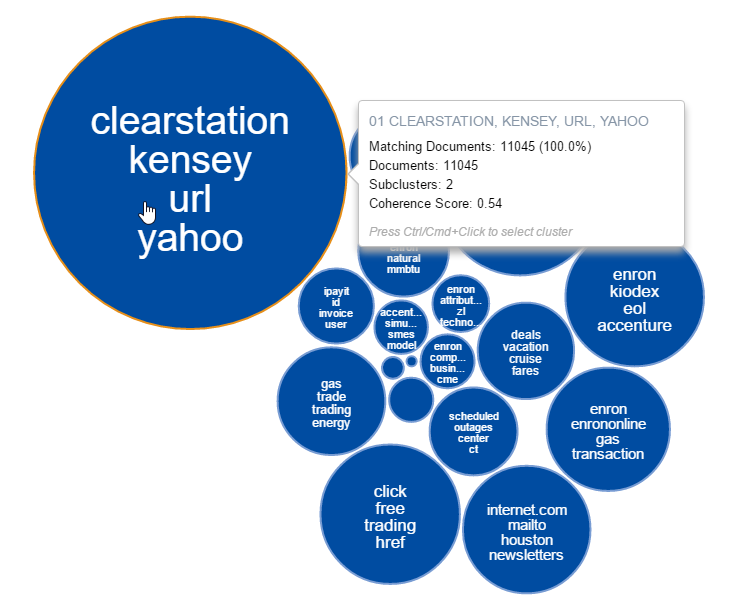
Clustering is a useful tool in any document review and should be considered alongside other analytics features when determining workflow.
Cluster Coherence
There is useful information stored relating to each cluster including, the number of documents contained with the cluster, the number of sub-clusters or categories within the cluster and the coherence score. The latter is an indication of how closely the documents are related within the cluster itself. The closer the coherence score to 1.0, the greater the relationship between the group of documents. The closer the coherence score to 0.0, highlights a group of documents more loosely related.
By clicking into each circle, the user can drill down further into the cluster, locating the sub-clusters within. This breaks down the cluster into smaller groups of conceptually similar documents. It can also be beneficial to locate ‘nearby clusters’. This allows for visualisation of clusters which are similar in concept to a cluster of particular interest.
The example below shows the cluster selected in the centre, with the remaining clusters around the edge. The clusters nearer the centre have a higher conceptual likeness. Those further away from the centre are less similar to the selected cluster.
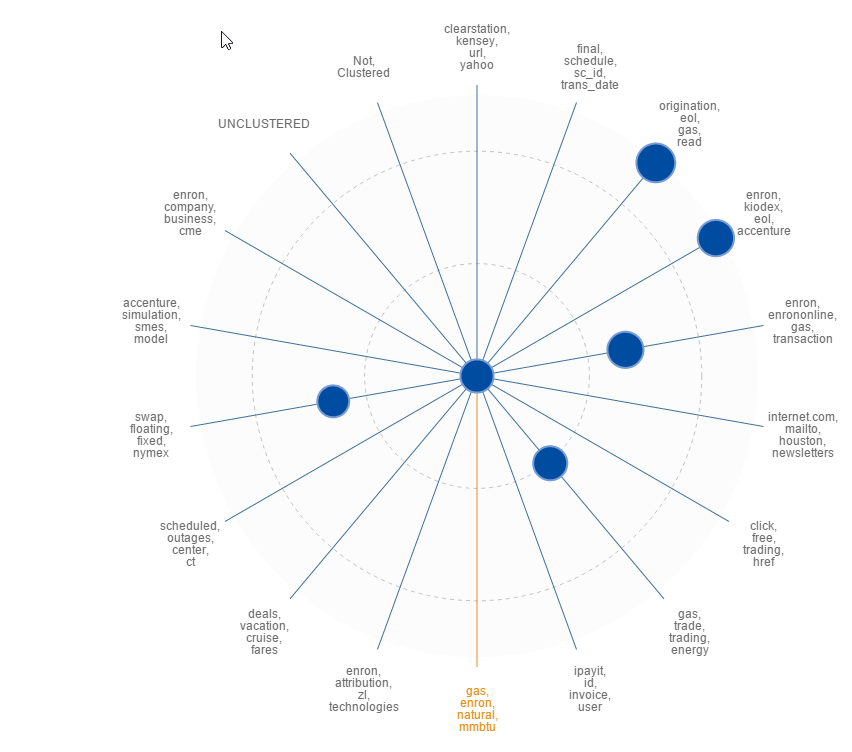
This can assist in identifying which clusters are of most interest, prioritising the review of documents most likely to be key to the case.
Filtering
Filters can also be applied to the cluster visualisation pane, setting conditions and logic groups to target a subset of documents, narrowing down the results further. Conditions can then be added to the selected cluster, using the filter pane and adding criteria such as a particular document extension or date range. Running this search applies a heat map to the clusters, highlighting which clusters contain the highest concentration of documents meeting the specified criteria. The darker the shade of blue, the more documents contained within the cluster.
The below chart shows a cluster selected (outlined in blue) with a condition set to show emails within this cluster;
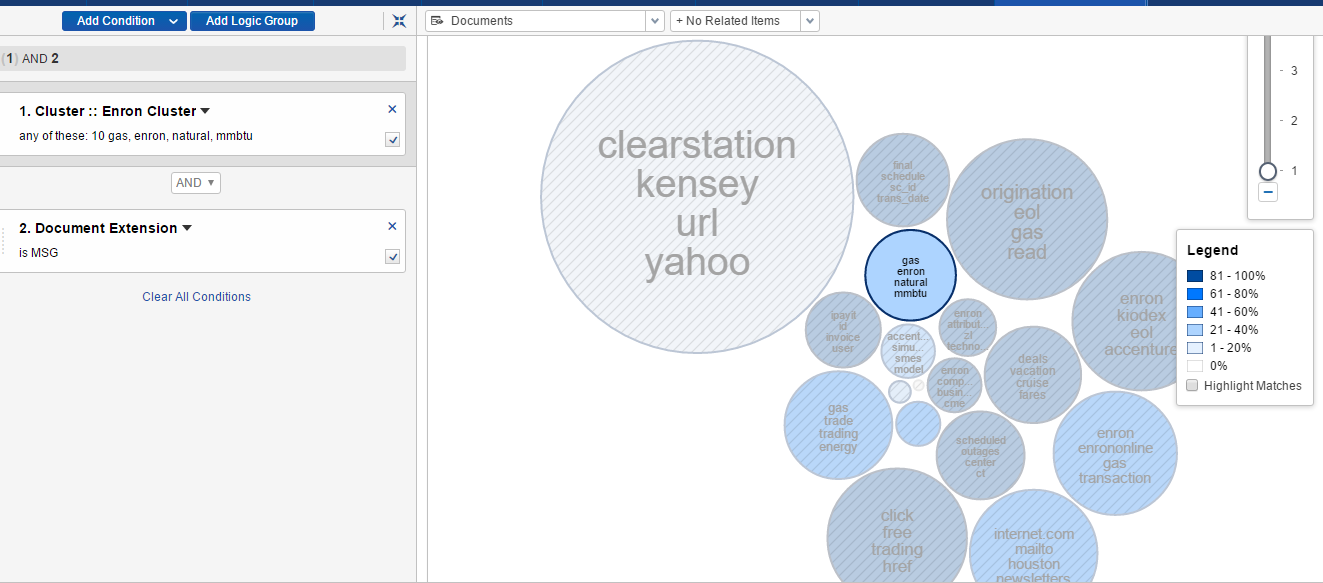
In addition to this cluster visualisation chart, the documents matching the search criteria are also listed for review. Not only can clustering be used to analyse topics within the data set, it can be a useful tool in carrying out quality control checks.
This can be used at the end of a review by creating a filter over the clusters to look at the documents coded as ‘relevant’ or ‘hot’. This determines the clusters containing the highest concentration of relevant documents. These clusters can then be prioritised for review to ensure coding consistency around groups of conceptually similar documents.
Overall, clustering is a useful tool in any document review and should be considered alongside other analytics features when determining workflow.
About Paula Forrest | eDiscovery Specialist
With a comprehensive skillset in advanced eDiscovery software and a qualified Relativity Certified Administrator, Paula specialises in social media investigations. She possesses a degree in BA (Hons) Criminology & Sociology, and a Masters qualification in Forensic Document Analysis. Her previous role as an Intelligence Analyst within the Cheshire Constabulary earned her a Chief Constable’s Commendation and two Chief Superintendent’s Commendations. This was awarded for exceptional analytic skills within high profile cases.
Call us today and speak with a Forensic Specialist
Send an enquiry to our experts
After submitting an enquiry, a member of our team will be in touch with you as soon as possible
Your information will only be used to contact you, and is lawfully in accordance with the General Data Protection Regulation (GDPR) act, 2018.